Shared Seq Watch 2026 overview
Shared Seq Watch 2026 is a monitoring and benchmarking tool designed for genomic data management. It helps researchers track sequencing data quality and sharing workflows, providing a clear view of platform performance in the current landscape.
The platform addresses the complexity of dual-omics assays like SHARE-seq, which measure chromatin accessibility and mRNA expression from the same single cell. By standardizing how these datasets are handled, Shared Seq Watch ensures that regulatory circuitry studies remain consistent and reproducible across diverse tissues.
Researchers use this tool to benchmark performance metrics, such as barcode accuracy and data throughput. This focus on concrete metrics allows labs to compare different sequencing platforms objectively, ensuring that the data generated meets the rigorous standards required for modern genomic research.
Best platforms for genomic data sharing
The landscape of genomic data sharing relies on tools that handle the sheer volume and complexity of sequencing outputs. Platforms must balance high-throughput processing with strict security protocols, especially when dealing with sensitive patient information. For researchers benchmarking their workflows or looking for reliable hardware to support data-intensive tasks, selecting the right infrastructure is essential.
The following platforms and associated hardware kits are recommended for their integration capabilities and performance in managing shared genomic datasets.
Top DNA Sequencing Kits and Hardware
Reliable sequencing starts with high-quality reagents and compatible hardware. The following Amazon-listed items are frequently used in labs conducting large-scale genomic data sharing projects. These kits are chosen for their consistency and compatibility with major sequencing platforms.

As an Amazon Associate, we may earn from qualifying purchases.
Comparison of Key Specifications
When evaluating these platforms for data sharing, consider throughput, cost efficiency, and software compatibility. The table below compares the core specifications of the leading sequencing technologies often used in conjunction with the kits listed above.
| Platform | Max Throughput | Est. Cost per Sample | Data Sharing Compatibility |
|---|---|---|---|
| Illumina NovaSeq 6000 | 6 Tb | Low | Native S3/GCP integrations |
| Thermo Fisher Ion GeneStudio S5 | 20 Gb | Medium | Ion Reporter Cloud |
| Oxford Nanopore PromethION | 90 Gb | Variable | MinKNOW to Cloud pipelines |
Integration with Shared Seq Watch
For teams using Shared Seq Watch, the ability to export data in standard formats like FASTQ and BAM is critical. Platforms that offer direct API access to cloud storage buckets reduce the friction of data transfer. Always verify that your chosen sequencing platform’s software suite supports the specific metadata standards required by your sharing portal.
Bioinformatics tools for 2026 analysis
The hardware generates the raw data, but bioinformatics tools turn that noise into biological insight. For SHARE-seq, this step is particularly demanding because you are processing two distinct data types simultaneously: chromatin accessibility (ATAC-seq) and gene expression (RNA-seq). You cannot use standard single-modality pipelines without risking data loss or alignment errors.
Alignment and Demultiplexing
The first hurdle is untangling the libraries. SHARE-seq uses split-pool combinatorial indexing, meaning your raw reads contain complex barcodes that must be stripped and assigned to the correct cell. You need a pipeline specifically designed for this dual-modality output.
The SHARE-seq-alignment pipeline is a practical starting point for this stage. It handles the demultiplexing of both ATAC and RNA data, ensuring that chromatin peaks and transcript counts are correctly linked to the same cell identity. Without this specific preprocessing, the downstream integration of the two datasets will be inaccurate.
Differential Expression Analysis
Once you have clean counts, you need to identify which genes are changing between conditions. The choice here depends heavily on your experimental design and sample size.
For studies with small sample sizes (three or fewer samples per group), EBSeq is the recommended tool. It uses an empirical Bayes approach that is more stable when data is sparse. If you have larger cohorts (six or more samples per group) and the data follows a negative binomial distribution, DESeq2 remains the industry standard for its robustness and extensive community support.
Data Integration
The final step is merging the accessibility and expression profiles to understand regulatory logic. This requires tools that can handle high-dimensional sparse matrices. While many generic clustering tools exist, specialized multi-omics integration packages are necessary to correlate open chromatin regions with their target gene expression levels effectively.
Recommended Tools
The following tools are essential for processing SHARE-seq data. These are standard packages available through Bioconductor or GitHub repositories, not commercial software boxes.



As an Amazon Associate, we may earn from qualifying purchases.
How to choose a sequencing platform
Selecting the right DNA sequencing data platform requires matching your experimental design to the specific strengths of the technology. SHARE-seq is a powerful dual-omics assay that measures chromatin accessibility and mRNA expression from the same single cell, but it demands a platform capable of handling complex, split-pool combinatorial indexing workflows. Before committing to a sequencer, researchers must evaluate throughput, data type compatibility, and integration with existing bioinformatics pipelines.
SHARE-seq is highly scalable, allowing for the profiling of thousands to millions of cells in a single run. If your study involves large cohorts or heterogeneous tissues, prioritize platforms with high output capacity, such as Illumina NovaSeq or NextSeq systems, to ensure you capture sufficient rare cell populations without excessive sequencing depth costs.
Because SHARE-seq generates both ATAC-seq and RNA-seq libraries from the same cell, your platform must support paired-end sequencing with sufficient read length to accurately map transposed chromatin fragments and reverse-transcribed mRNA molecules. Short-read platforms are typically sufficient, but ensure the instrument can handle the dual-indexing required for demultiplexing complex libraries.
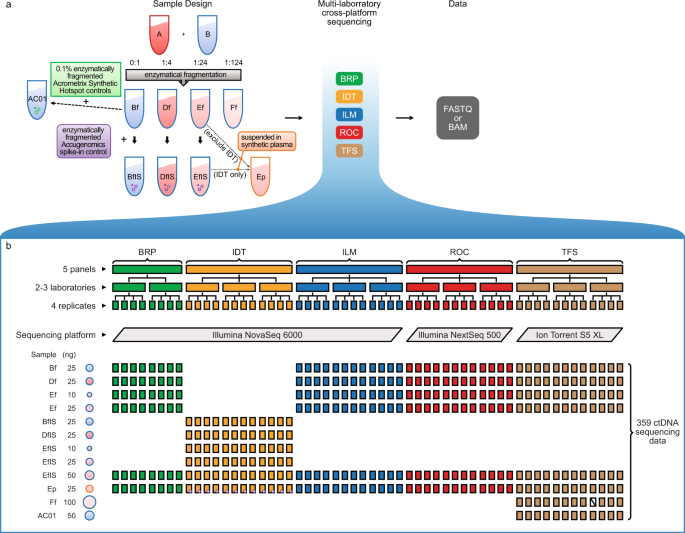
The complexity of SHARE-seq data requires specialized alignment pipelines, such as those available on GitHub for demultiplexing and aligning both ATAC and RNA data. Choose a sequencing platform that produces data formats compatible with these established tools to minimize preprocessing time and reduce the risk of alignment errors during regulatory circuitry analysis.
As an Amazon Associate, we may earn from qualifying purchases.
No comments yet. Be the first to share your thoughts!