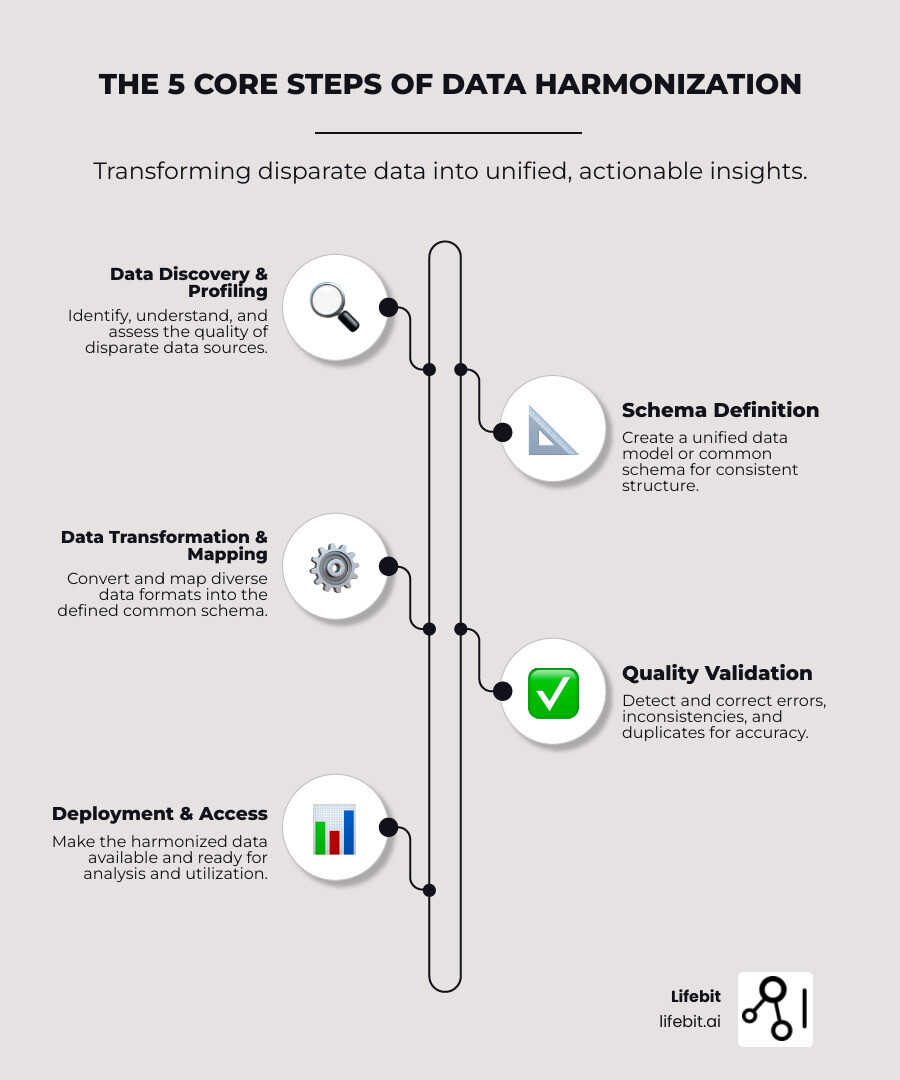
Why shared sequences matter in 2026
Shared sequences are reusable data assets that serve as the backbone of modern interoperable workflows. In 2026, AI-driven harmonization has shifted these sequences from simple utility scripts to critical infrastructure. They allow technical teams to treat data generation logic as a standardized component rather than a bespoke script.
The rise of AI-driven interoperability means these assets must be harmonized automatically. When data flows between systems, shared sequences provide a consistent reference point. This reduces the friction of integration and minimizes the risk of data drift.
For technical teams, the value is clear: reuse, reliability, and speed. By centralizing sequence logic, organizations can maintain data integrity without rewriting code for every new integration. This approach is essential for scaling operations in a complex, multi-cloud environment.
Cloud-native sequence generation
The shift from local to distributed generation is the defining characteristic of modern cloud data integration. In legacy on-premise setups, sequence generators often relied on local database instances, creating bottlenecks when data moved across geographic boundaries. Cloud-native platforms like Informatica IDMC have replaced this fragmented approach with shared sequences—reusable, centralized objects that can be accessed by multiple Sequence Generator transformations simultaneously.
This architecture eliminates the need for complex replication logic. Instead of maintaining separate sequence objects in each data warehouse or staging area, engineers define the sequence once in the cloud control plane. The platform then handles the distributed allocation, ensuring unique, gap-free values regardless of where the transformation runs. This reduces operational overhead and prevents key collisions that frequently plagued hybrid deployments.
The result is a more predictable data pipeline. By centralizing the generation logic, organizations can scale their data integration workloads without worrying about sequence exhaustion or synchronization errors. This approach supports the high-throughput demands of 2026 data harmonization, where data flows between multi-cloud environments are the norm, not the exception.
AI automates data harmonization
Artificial intelligence is shifting data harmonization from a manual mapping exercise to an automated pipeline. Instead of engineers manually defining rules for every new data source, machine learning models analyze schema structures to identify relationships and standardize formats across disparate systems. This approach significantly reduces the manual effort required to maintain data interoperability.
AI-driven tools use natural language processing to interpret column names and data types, automatically generating transformation logic. For example, if one system uses "DOB" and another uses "birth_date," an AI model can recognize these as equivalent fields and apply the correct date formatting without human intervention. This ensures consistent data structures across integrated platforms, minimizing errors caused by manual entry or misinterpretation.
The result is a more resilient data infrastructure. As new sources are onboarded, the system learns from previous mappings, accelerating future integration tasks. This continuous learning loop allows organizations to scale their data operations without proportionally increasing their engineering headcount, keeping data harmonization costs predictable and manageable.
How technical teams benchmark shared sequence performance
Benchmarking shared sequences requires isolating three core metrics: throughput, latency, and error rates. Technical teams use these numbers to determine if a sequence generator is becoming a bottleneck in the data pipeline. When throughput drops, it usually indicates resource contention. When latency spikes, it often points to network overhead or serialization delays.
Teams typically run load tests against the sequence generator transformation. They measure how many unique IDs the system can produce per second under steady load. They also track the time between sequence generation and the downstream consumer receiving the data. High error rates during these tests reveal instability in the shared state management.
| Metric | Target | Impact of Failure |
|---|---|---|
| Throughput | > 10k IDs/sec | Data ingestion backlogs |
| Latency | < 50ms | Real-time processing delays |
| Error Rate | < 0.1% | Data corruption or loss |
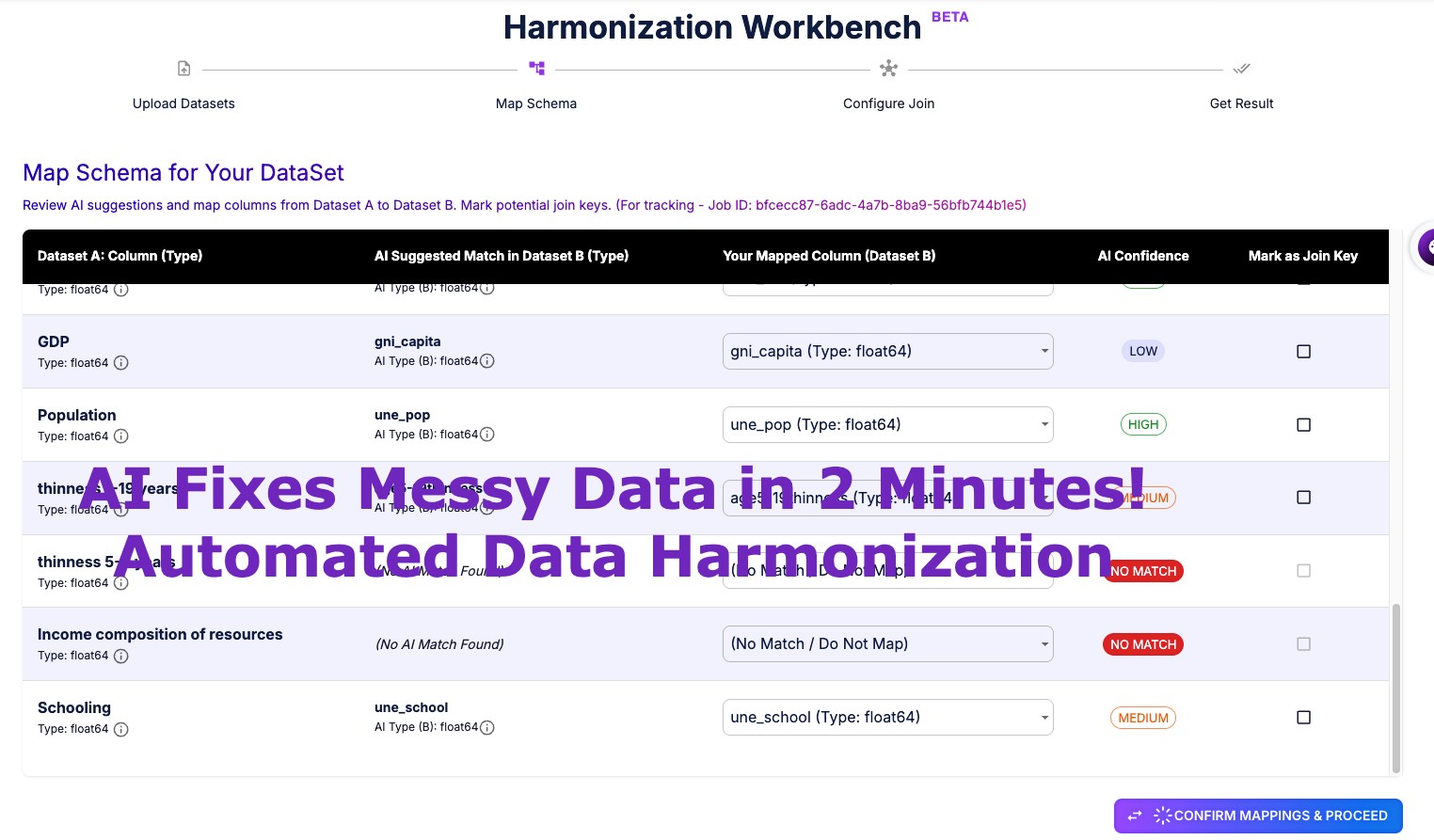
The image above illustrates the kind of dashboard teams use to monitor these metrics in real time. It shows how visualizing sequence generation rates helps engineers spot anomalies before they impact production. By tracking these benchmarks, teams can optimize their shared sequence configurations for maximum reliability.
Ethical data sharing frameworks
Technical interoperability means little if the underlying data governance lacks ethical grounding. As shared sequence databases grow, the industry must align technical standards with frameworks that protect privacy and ensure equitable benefit-sharing.
Organizations like PHA4GE are establishing practical protocols for host sequence depletion, a critical step in responsible pathogen genomics. By removing human DNA from environmental samples, researchers can share sensitive data without compromising individual privacy, bridging the gap between open science and ethical compliance [PHA4GE].
Similarly, the post-2020 global biodiversity architecture emphasizes Digital Sequence Information (DSI) sharing. The new global deal outlines an open-access platform paradigm, ensuring that genetic data from biodiversity hotspots benefits the communities and nations where it originates. These frameworks demonstrate that ethical standards are not constraints on data flow, but essential infrastructure for sustainable scientific collaboration.
Shared Sequence Watch 2026 FAQ
What is a shared sequence in data integration? A shared sequence is a reusable generator object that multiple transformations can reference simultaneously. Instead of creating duplicate logic for each pipeline, you define the sequence once in the repository. This ensures consistent identifier generation across different data jobs.
How do shared sequences improve harmonization? They reduce redundancy and prevent data drift during harmonization. When multiple systems pull from the same sequence, they use identical numbering or timestamping rules. This uniformity makes it easier to match records across disparate sources without manual reconciliation.
Can shared sequences handle high-volume AI workloads? Yes, but they require careful indexing. Shared sequences often become bottlenecks if not distributed properly. Modern architectures use sharding or caching layers to handle the concurrency demands of AI-driven data pipelines, ensuring low-latency access for real-time harmonization tasks.
No comments yet. Be the first to share your thoughts!